0 JVM内存区域划分
我们都知道,jvm整体由4个部分组成,分别是:
-
类加载子系统(ClassLoader):负责把文件加载到内存中的 运行时数据区。
-
运行时数据区(Runtime Data Area):负组织java程序运行时,变量及数据在内存中的分布。
-
执行引擎(Execution Engine):是一个命令解析器,负责将字节码翻译成底层系统指令再交由CPU去执行。
-
本地库接口(Native Interface):调用其他语言的接口来实现整个程序的功能。
对于JVM的运行时数据区,不同虚拟机实现可能略微有所不同,但是整体来说可以划分为五大部分,如下图所示:
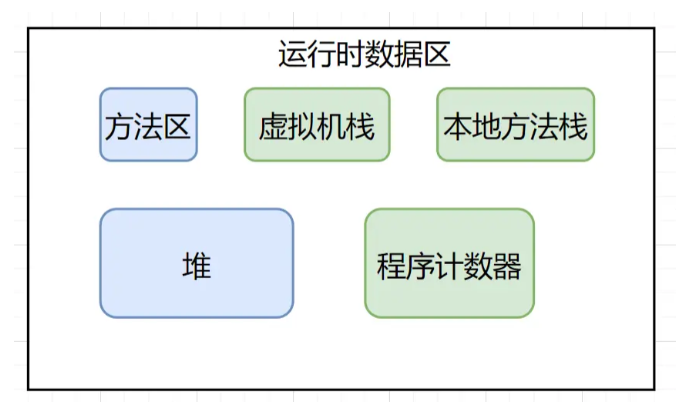
其中,方法区和堆是线程共享的区域,其他则是线程私有的。各区域职责如下:
-
程序计数器 也叫PC寄存器。是一块较小的内存空间。 在 JVM 规范中,每个线程都有自己的程序计数器,独立存储,互不影响,也就是说程序计数器是线程私有的。 如果当前线程执行的是一个 Java 方法,程序计数器记录的是正在执行的虚拟机字节码指令的地址,如果正在执行的是本地(Native)方法,则是空(Undefined)。 此内存区域是唯一一个在 JVM 规范中没有规定任何 OutOfMemoryError 情况的区域。
-
虚拟机栈 描述的是 Java 方法执行的线程内存模型,-Xss规定了每个线程堆栈的大小。每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧(Stack Frame)压入虚拟机栈,方法执行完毕栈帧出栈。 栈帧中存储着局部变量表、操作数栈、动态链接、方法出口等信息。
-
本地方法栈 与虚拟机栈类似,也是每个线程都会创建一个。区别是,虚拟机栈为虚拟机执行 Java 方法服务,本地方法栈则是为虚拟机使用到的本地(Native)方法服务。
-
堆 在虚拟机启动时创建,通过参数-Xms 和 -Xmx 设定初始堆大小和最大堆大小。它是Java内存管理的核心区域,用来存放 Java 对象实例,几乎所有的 Java 对象实例都被直接分配在堆上。 但是随着即时编译技术的进步和逃逸分析技术的逐渐成熟,栈上分配、标量替换优化手段将会导致一些微妙的变化,所有的对象都分配到堆上也渐渐变得不那么“绝对”了。
从 JDK1.7 开始已经默认开启逃逸分析,如果某些方法中的对象引用没有被返回或者未被外面使用(也就是未逃逸出去),那么对象可以直接在栈上分配内存。
-
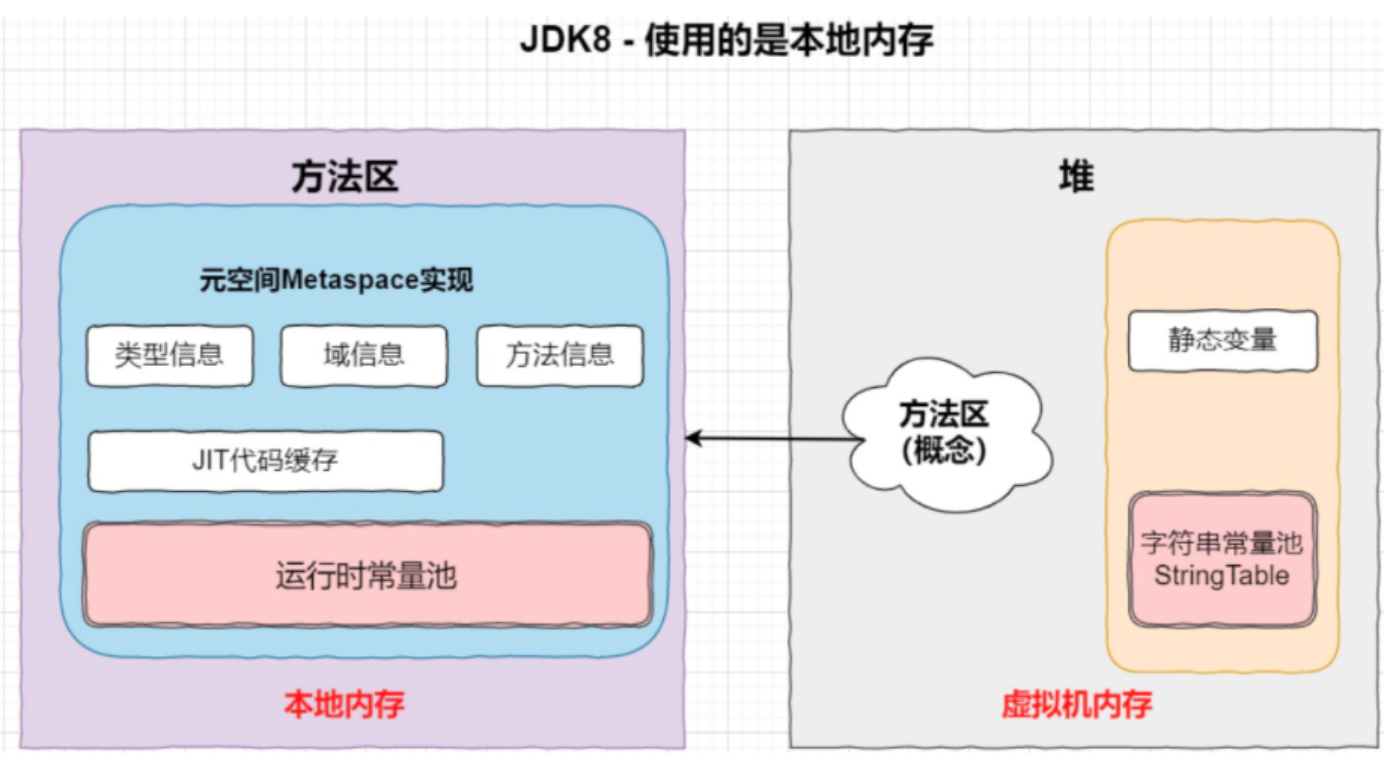
方法区 是一种逻辑规范,不同的虚拟机有不同的实现,用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。在HotSpot 中,之前是用永久代实现,接在堆内存后面的连续的一块区域,不过在 JDK6 的时候 HotSpot 团队就有放弃永久代逐步改为本地内存(Native Memory)来实现方法区的计划了, 到 JDK8 中彻底移除了永久代,将 JDK7 中永久代剩余的内容(主要是类的元数据)移到元空间(Metaspace)中。 移除永久代是为融合 HotSpot JVM 与 JRockit VM 而做出的努力,因为 JRockit 没有永久代,不需要配置永久代。
为什么抛弃永久代?
由于永久代的大小是有限的,并且 JVM 对永久代垃圾回收(如,常量池回收、类型的卸载)的效果比较难以令人满意, 我们通常使用 -XX:PermSize 和 -XX:MaxPermSize 设置永久代的大小, 32位机器默认的永久代大小为64M,64位的机器则为85M。 一旦类的元数据超过了设定的大小,程序就会耗尽内存,并出现内存溢出错误(OOM)。
1 各种变量及数据实际分布
变量 & 数据 & 对象
java中变量是一个内存位置的别名(指向内存地址,可更改)。一个变量会被分配一个数据类型,代表这个变量指向的地址存的是什么类型的数据。变量类型有三种:局部变量(声明在方法内部,包括形式参数)、实例变量(声明在类内部,方法之外,未有static修饰)、静态变量(类变量,声明在类内部,方法之外,且有static修饰)。
java中数据类型有两种:Primitive (基础数据类型) 和Non-Primitive (引用数据类型)。
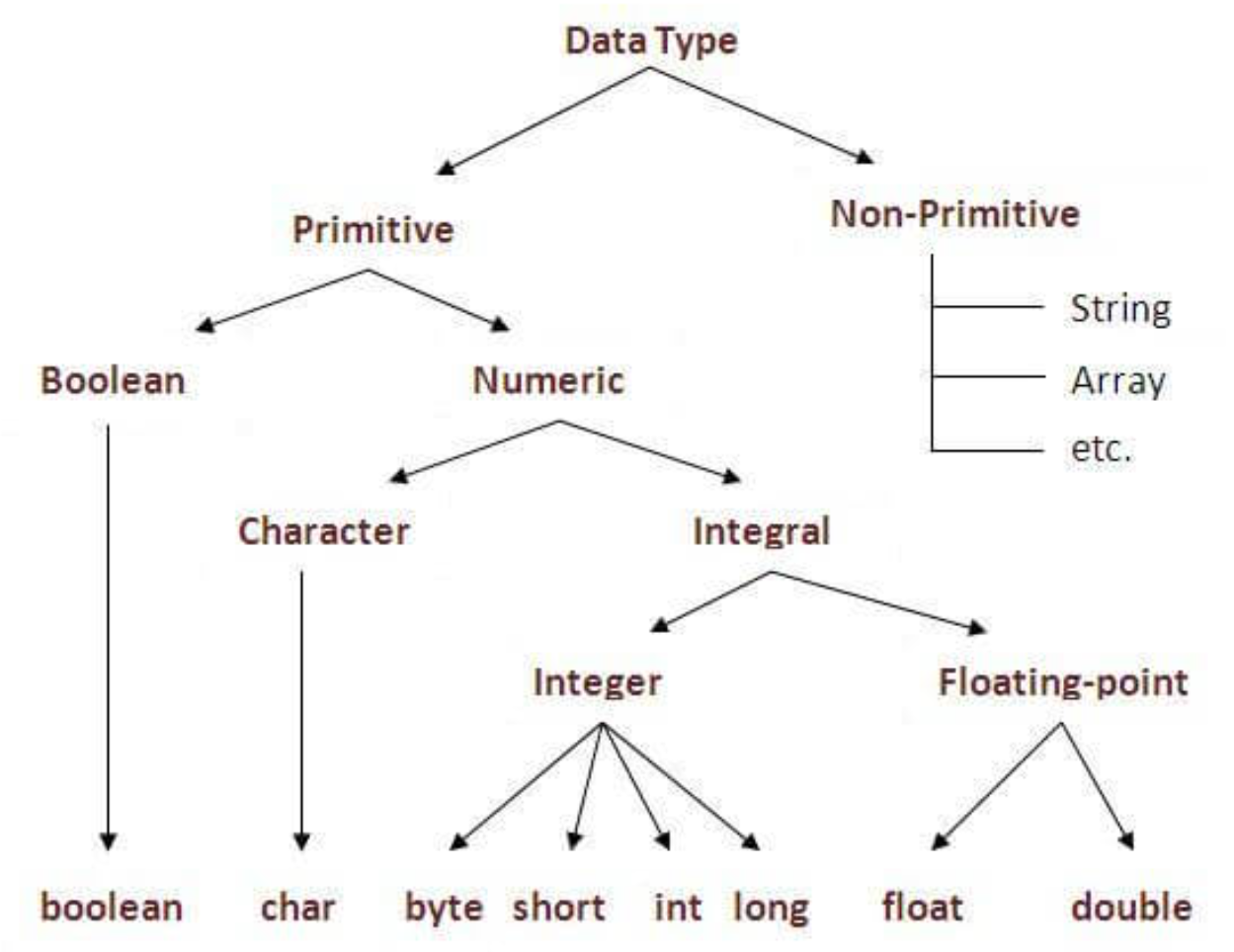
我们都知道在java中,一切皆对象,数据和变量都是依赖于对象而存在的,数据和变量的位置及数值会随着对象状态变更产生变化,因此对于代码在内存中的分布可以以对象为核心进行展开分析,根据对象的状态不同,来进行内存分析。按照方法的依次运行过程,变量与数据会进行合理分配。
我们知道所有对象的存储空间都是在堆中分配的,但是这个对象的引用却是在栈中分配的,那么jvm是如何对对象进行寻址的呢?
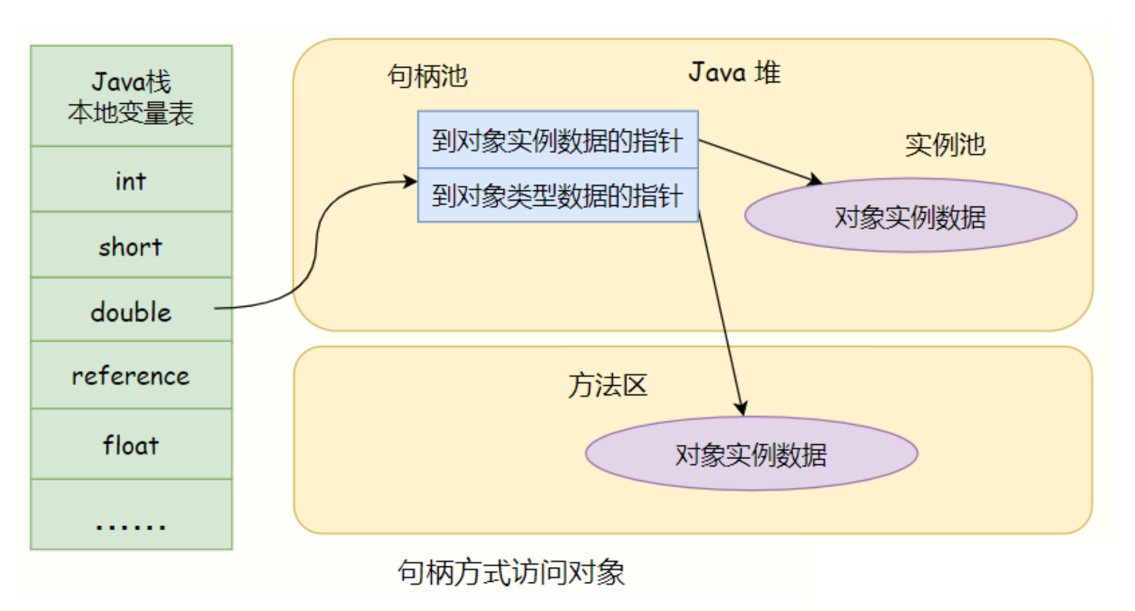
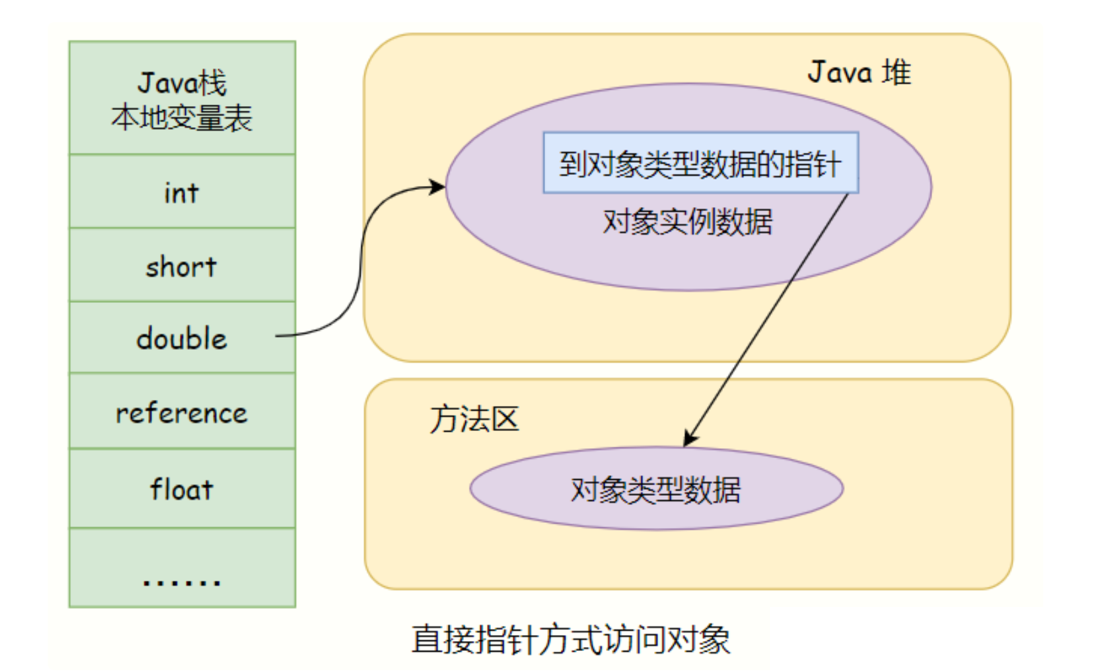
对于对象寻址,有两种方法:通过句柄或者直接指针;hotspot使用的是通过指针直接定位对象。
- 句柄定位,通过指针找到句柄,通过句柄找到对象。句柄:指向指针的指针,可以通过句柄作为中介寻址。
- 直接指针访问定位, 通过指针直接定位对象
java程序在启动后,jvm会先加载main方法所在的类文件,放入方法区,然后识别main方·法,从main方法开始进行代码执行(加载到main线程的虚拟机栈中),这个main方法就是静态方法,因此不需要创建对象即可作为程序的入口执行;一个java程序可以有多个入口(多个main方法);main方法也可以直接作为一个普通静方法进行调用;
在执行过程中,按需加载变量/数据/对象,其中局部变量直接放在虚拟机栈当前方法的栈帧中,全局变量(静态变量)放在方法区;加载对象的时候会先将对象类信息加载到方法区,然后在堆中创建相应的实例对象,最后在栈中创建相应实例对象的引用。
实际代码分析
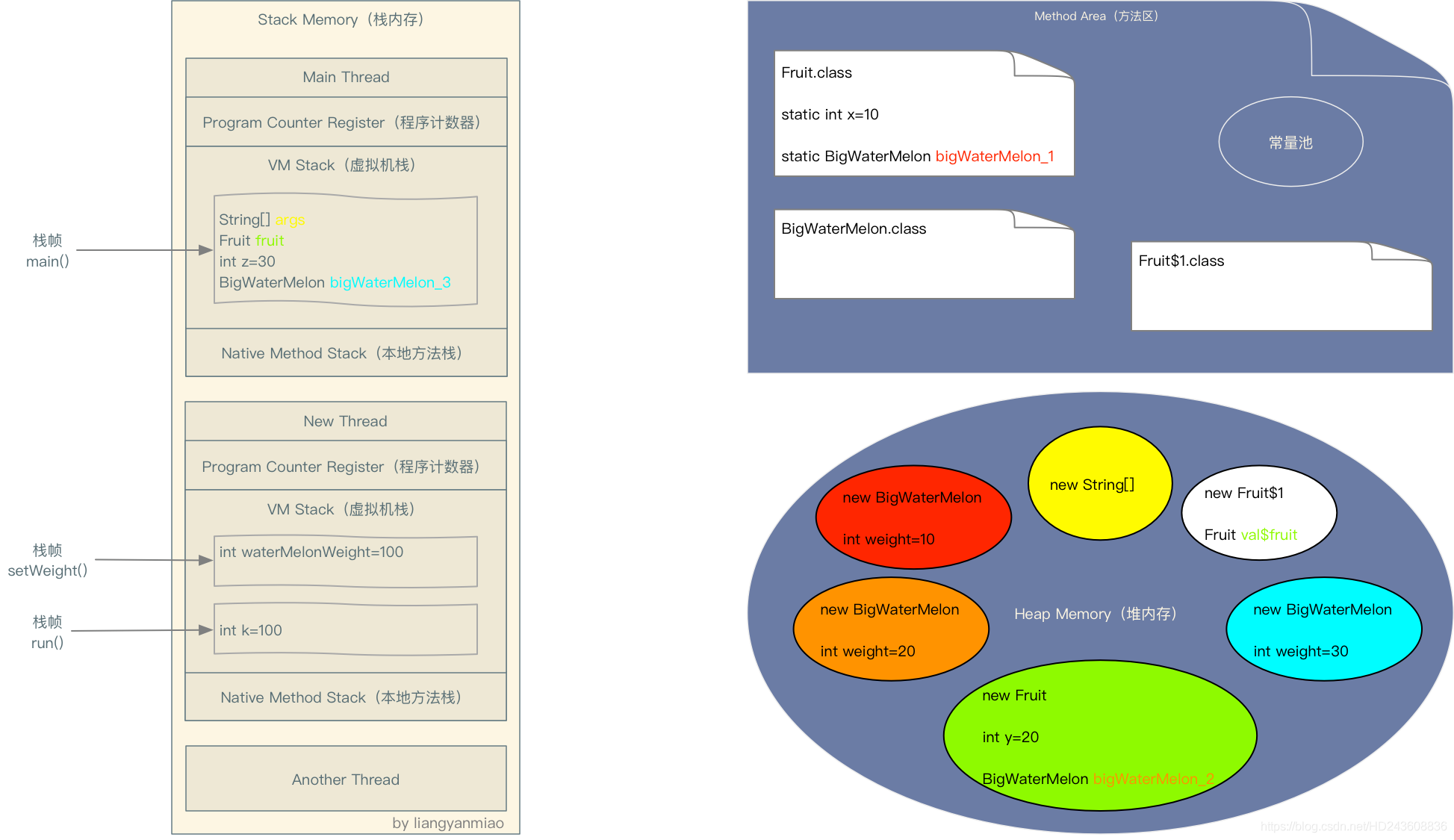
以下面代码为例解读各种类型的变量及数据在运行时数据区的分布情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
public class Fruit { //类信息放在方法区
final static int constantPrice = 50; // 静态变量在方法区
final static String constantName = "水果"; // 存在字符串常量池 引用存在方法区
static int staticPrice = 100; //方法区
static BigWaterMelon thin = new BigWaterMelon("皮薄", staticPrice);
int instancePrice = 200;
BigWaterMelon juicy = new BigWaterMelon("多汁", instancePrice);
public static void main(String[] args) {
Fruit fruit = new Fruit(); //堆中
//打印对象字段
printFields(fruit);
int mainThreadLocalPrice = 300;//栈中
BigWaterMelon sweet = new BigWaterMelon("超甜", mainThreadLocalPrice);//堆中
new Thread() { //新的线程,会创建新的虚拟机栈/程序计数器/本地方法栈
@Override
public void run() {
int subThreadLocalPrice = mainThreadLocalPrice;
setPrice(subThreadLocalPrice);
}
void setPrice(int price) {
fruit.juicy.setPrice(price);
fruit.thin.setPrice(price);
sweet.setPrice(price);
//打印对象字段
printFields(this);
}
}.start();
}
}
//大西瓜类
class BigWaterMelon {
//品种
private String name;
//价格
public int price;
public BigWaterMelon(String name, int price) {
this.name = name;
this.price = price;
}
public void setPrice(int price) {
this.price = price;
}
}
分布图如下:
总结
new出的对象存储堆中,基本类型字面量为常量或静态变量时,存储在常量池(方法区), 为成员变量存储在堆中,为局部变量存储在栈中。

2 各种常量池总结
除了运行过程中的一些常规对象的分布外,java中提供了一些池化技术,方便对一类数据的集中管理,其中包括:静态常量池、运行时常量池、字符串常量池。
静态常量池
静态常量池是针对每个被加载进入内存的class文件解析后,存放各个字面量值,符号引用的数据。简而言之,静态常量池属于某个类的字节码文件,属于单个类的自己的常量池。静态常量池存在于字节码文件中,经过加载后一些数据会被放到运行时常量池。
运行时常量池
运行时常量区就是当前运行类加载所有相关类(如父类、实现类、一些系统类、输出流等)的字节码文件后,把他们所有的静态常量池的数据汇总到一起,存放在该进程的运行时常量池中,再加上该类运行期解析后才能够获得的方法或者字段引用,就组成了运行时常量池。
如下图所示,运行时常量池存在于方法区中:
字符串常量池
作用:为了减少在jvm中创建的字符串的数量,虚拟机维护了一个字符串常量池。当创建String对象时,jvm会先检查字符串常量池,如果这个字符串的常量值已经存在在池中了,就直接返回池中对象的引用,如果不在池中,就会实例化一个字符串并放入池中。
位置:Java6及以前,字符串常量池存放在永久代。Java7中Oracle的工程师对字符串池的逻辑做了很大的改变,即将字符串常量池的位置调整到Java堆内。String在jdk8及以前内部定义了final char [] 数组用于存储字符串数据。jdk9时改为byte[]。
特性举例:
1
2
3
4
5
6
String sl = "abc";//字面量的定义方式 会先在字符串常量池中寻找是否有hello,有的话就直接返回引用即可,没有将创建一个然后返回引用,堆中不会有对象出现;因此最多只会在字符串常量池中创建一个对象"abc"。
String s2 = "a" + "bc"; ///编译器会在编译期就自动优化,因此最多还是只会在字符串常量池中创建一个对象"abc"
String s3 = new String ("abc"); //显式new的方式创建,如果abc这个字符串常量不存在,则会在字符串常量池创建一个"abc",然后再把字符串"abc"复制到堆中, 并把这个对象的引用交给s3, 因此最多创建了两个对象, 一个在堆中一个在字符串常量池中。
参考资料
Java中是否可以调用一个类中的main方法? - weizhxa - 博客园 (cnblogs.com)
Java中的变量与数据类型_leunging的博客-CSDN博客_java变量数据类型
JVM存储位置分配——java中局部变量、实例变量和静态变量在方法区、栈内存、堆内存中的分配